
Large Language Modelle, oft als LLMs abgekürzt, sind wie die Sprachwunder der künstlichen Intelligenz-Welt. In diesem Artikel nehmen wir dich mit auf eine Reise in die faszinierende Welt der Large Language Modelle, um dir nicht nur einen gründlichen Überblick über ihre Funktionen und Anwendungen zu bieten, sondern auch mithilfe anschaulicher Analogien ein besseres Verständnis zu vermitteln.
Die Magie der Large Language Modelle

Stell dir LLMs als riesige Bibliotheken vor, die mit Büchern aus allen Ecken der Welt gefüllt sind. Doch anstelle von Büchern bestehen diese Bibliotheken aus Textdaten, die aus dem gesamten Internet, Büchern, Zeitschriften und wissenschaftlichen Arbeiten gesammelt wurden. Diese „Bibliotheken“ sind in Wirklichkeit leistungsstarke Computerprogramme, die in der Lage sind, die Feinheiten der natürlichen Sprache zu verstehen und anzuwenden.
Denk an LLMs wie Sprachkünstler, die aus dieser riesigen Sammlung von Texten lernen, wie Wörter kombiniert werden können, welche Themen wichtig sind und wie man zusammenhängende und sinnvolle Texte erstellt. Sie sind in der Lage, wie Sprachdetektive Muster in der Sprache zu erkennen und können verschiedene Aufgaben im Bereich der Sprachverarbeitung meistern.
Large Language Modelle
in der Anwendung
Die Anwendungsmöglichkeiten von Large Language Modellen sind so vielfältig wie deine Vorstellungskraft selbst. Hier sind einige konkrete Beispiele, um ihre beeindruckenden Fähigkeiten zu verdeutlichen:
Fragen beantworten
Stell dir vor, du hast einen persönlichen Assistenten, der dir immer die besten Antworten auf deine Fragen gibt. Zum Beispiel kann er dir erklären, wie Photosynthese funktioniert oder historische Ereignisse wie den Zweiten Weltkrieg erläutern.
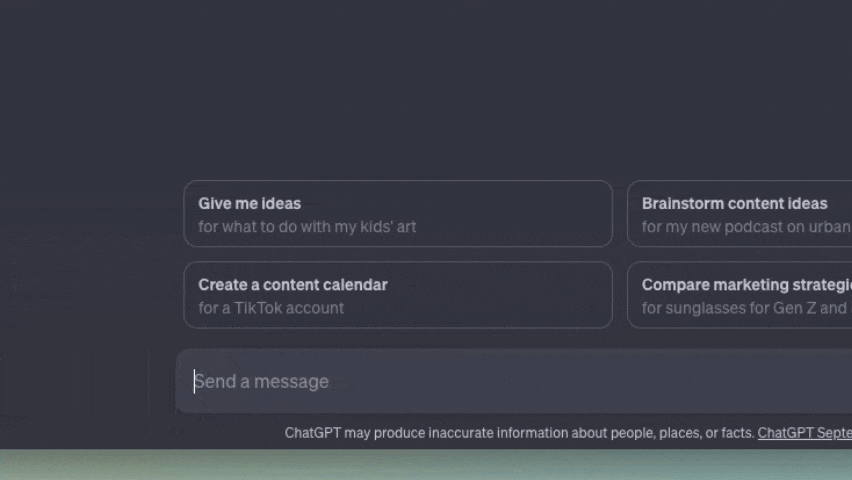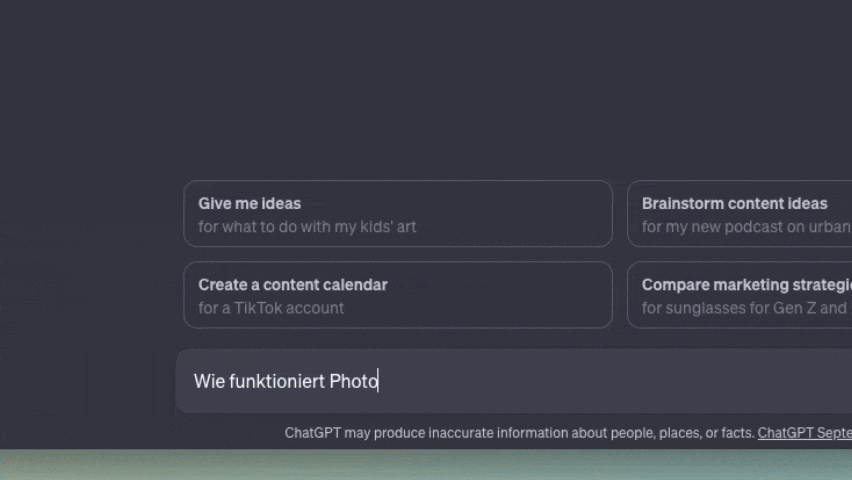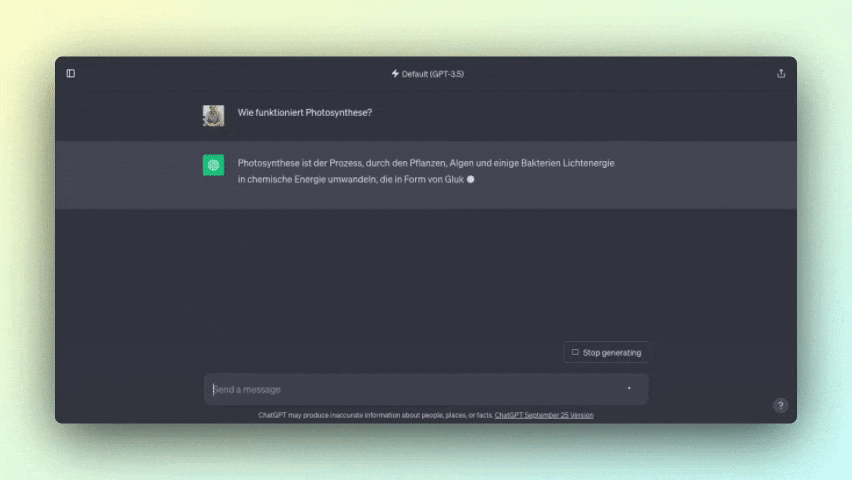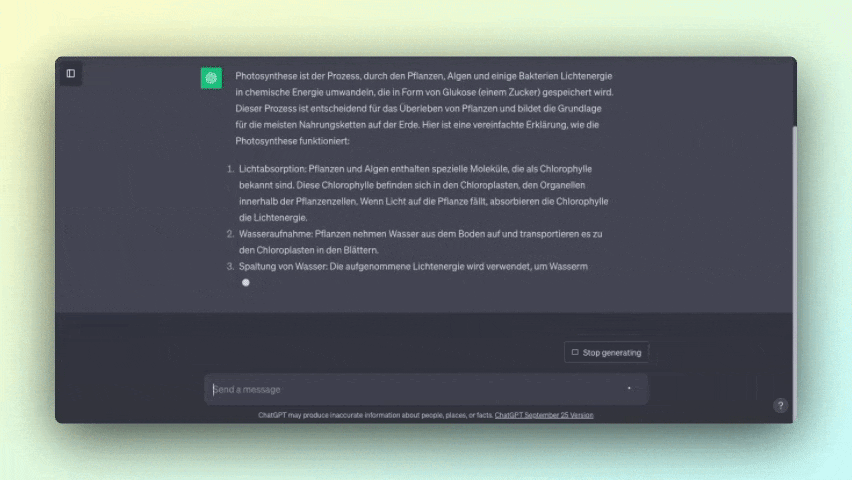
Texte zusammenfassen
Denk an einen talentierten Autor, der dicke Bücher in kurze, prägnante Zusammenfassungen verwandeln kann. Dies kann nützlich sein, um lange wissenschaftliche Artikel auf die wichtigsten Erkenntnisse zu reduzieren.
Texte übersetzen
Stell dir einen Dolmetscher vor, der mühelos zwischen verschiedenen Sprachen hin- und herwechseln kann, um die Kommunikation zu erleichtern. So kann er beispielsweise Texte von Deutsch nach Spanisch übersetzen, um internationale Geschäftsbeziehungen zu unterstützen.
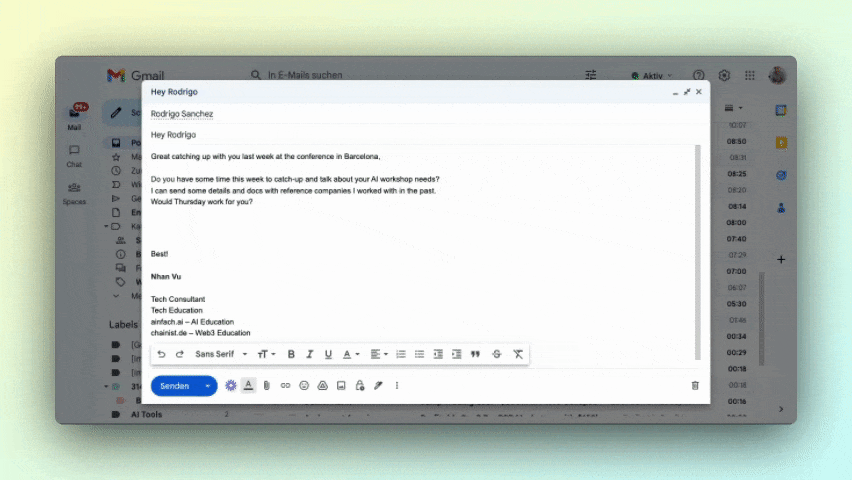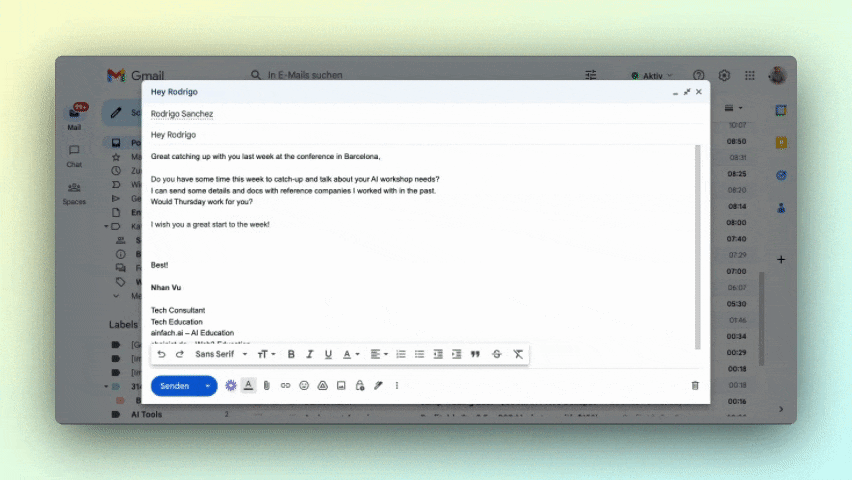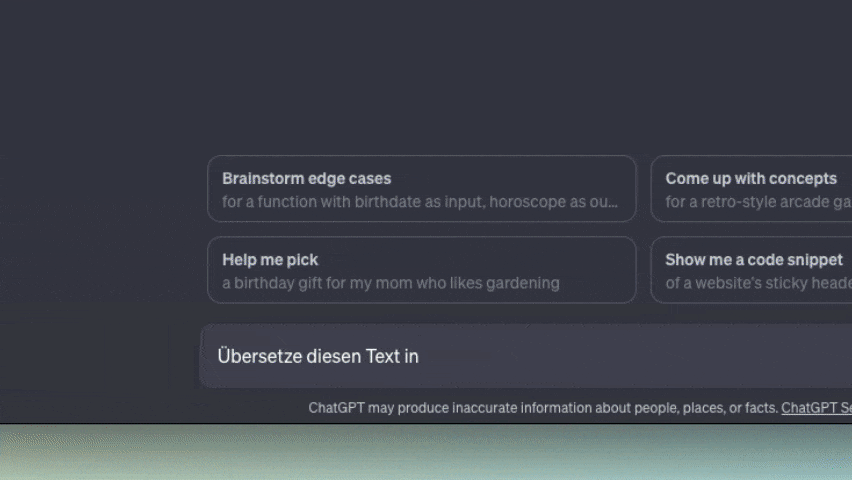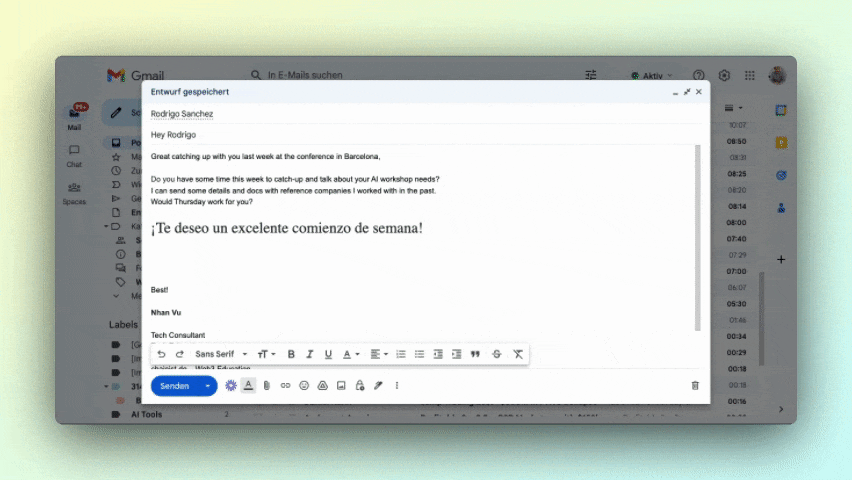
Texte vervollständigen
Ähnlich wie ein Puzzlespiel, bei dem fehlende Teile ergänzt werden, können LLMs Sätze nahtlos vervollständigen. Zum Beispiel könnten sie dir bei der Formulierung von E-Mails oder Geschäftsberichten helfen.

Texte generieren
Denk an einen Schriftsteller, der endlose Geschichten und Artikel zu einer Vielzahl von Themen verfassen kann. LLMs können auch kreative Gedichte, Liedertexte oder sogar Drehbücher für Filme erstellen.

Programmcode schreiben
LLMs sind wie erfahrene Programmierer, die Code in verschiedenen Programmiersprachen schreiben können. Das bedeutet, sie könnten dir bei der Entwicklung von Softwareanwendungen oder Websites helfen.
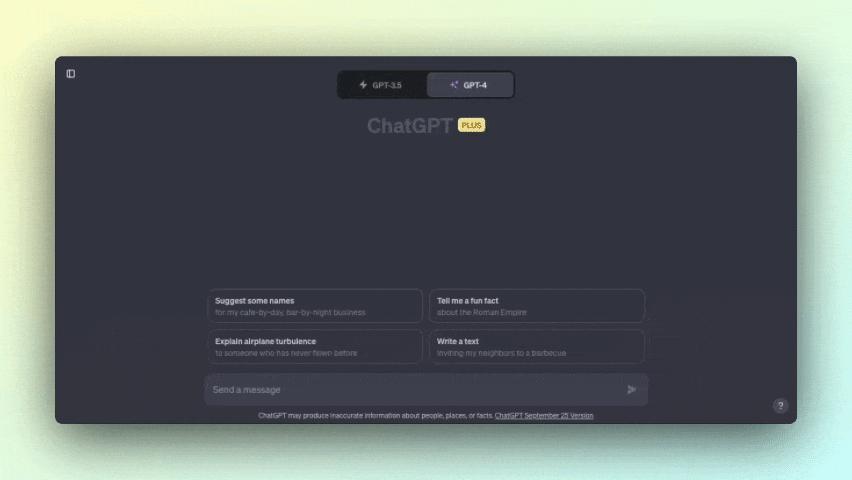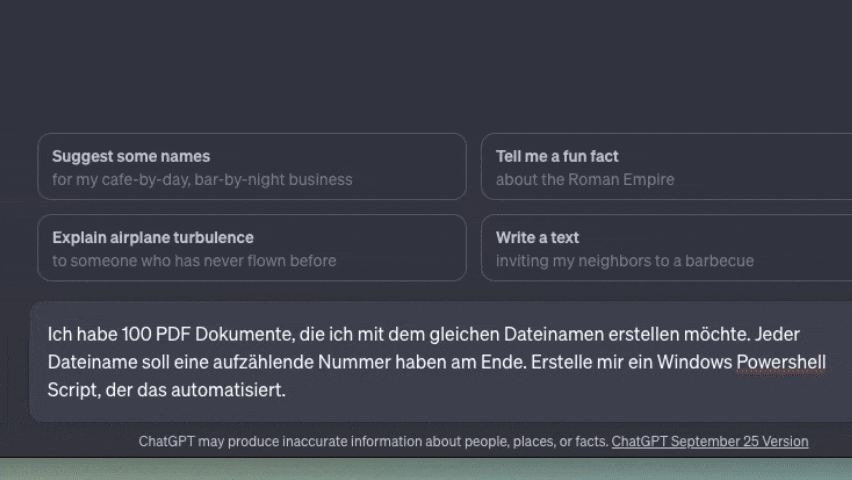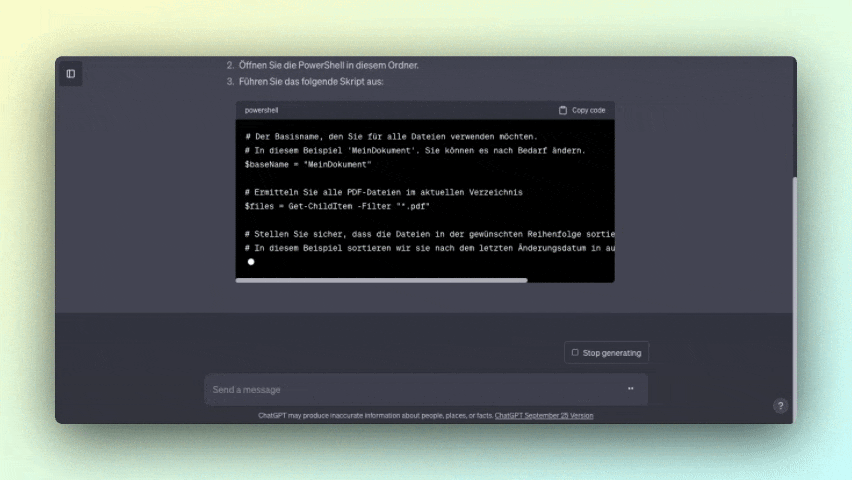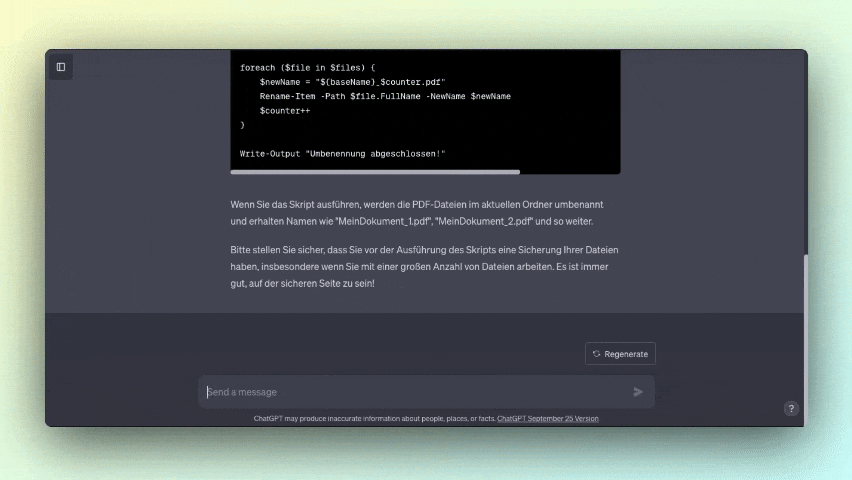
Dialoge führen
Stell dir vor, du könntestest ein Gespräche mit einer virtuellen Assistenz führen, die auf deine Fragen und Anliegen eingeht. Zum Beispiel könntest du mit einem Chatbot interagieren, der dir bei der Lösung von technischen Problemen oder der Planung von Reisen hilft.
Nachdem du jetzt die wichtigsten Anwendungsfelder entdeckt hast, lass uns gemeinsam einen Überblick über die wichtigsten Entwicklungen im Bereich Sprachverarbeitung der Vergangenheit verschaffen.
Die Evolution von
Large Language Modellen
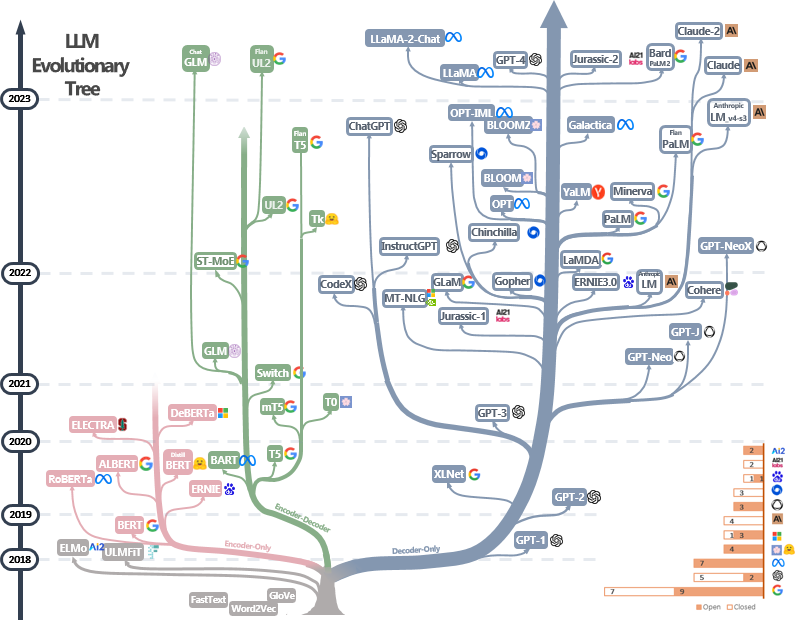
Bildquelle: Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond
Die Entwicklung von Large Language Modellen (LLMs) ist das Ergebnis einer langen Reise in der Forschung zur Verarbeitung natürlicher Sprache (NLP). Hier ist ein Überblick über die Meilensteine auf dieser Reise:
1957
George A. Miller veröffentlicht “The Magical Number Seven, Plus or Minus Two”. Diese Arbeit legt den Grundstein für die Forschung zur Verarbeitung natürlicher Sprache (NLP), aber sie ist nicht die erste Arbeit in diesem Bereich. Bereits in den 1940er und 1950er Jahren gab es einige Vorläufer der NLP-Forschung, wie zum Beispiel die Arbeiten von Alan Turing, Claude Shannon oder Noam Chomsky.
1960er Jahre
Die ersten NLP-Systeme werden entwickelt, aber sie sind nicht nur sehr einfach, sondern auch sehr begrenzt. Sie basieren auf regelbasierten oder statistischen Ansätzen, die nur für bestimmte Domänen oder Sprachen funktionieren. Sie sind auch sehr anfällig für Fehler und können nicht mit der Vielfalt und Ambiguität der natürlichen Sprache umgehen.
1970er Jahre
Die Entwicklung von NLP-Systemen schreitet voran, aber es gibt auch einige Rückschläge. Zum Beispiel scheitert das Projekt SHRDLU von Terry Winograd, das eine natürlichsprachliche Schnittstelle für eine virtuelle Welt schaffen wollte. Es stellt sich heraus, dass die Komplexität der natürlichen Sprache viel höher ist als erwartet.
1980er Jahre
Die Entwicklung von NLP-Systemen setzt sich fort, aber es gibt auch einige Herausforderungen. Zum Beispiel wird das Problem des Wissenserwerbs erkannt, das darin besteht, dass NLP-Systeme nicht nur Sprache, sondern auch Weltwissen benötigen, um sinnvolle Interpretationen und Antworten zu liefern. Dieses Weltwissen ist jedoch schwer zu formalisieren und zu speichern.
1990er Jahre
Die Entwicklung von NLP-Systemen wird durch die Verfügbarkeit großer Datenmengen und die Fortschritte in der Computerleistung vorangetrieben, aber es gibt auch einige Kritik. Zum Beispiel wird das Problem der Evaluierung erkannt, das darin besteht, dass NLP-Systeme nicht nur nach ihrer Leistung, sondern auch nach ihrer Relevanz und Nützlichkeit für die Nutzer bewertet werden müssen. Dies ist jedoch schwer zu messen und zu vergleichen.
2000er Jahre
Die Entwicklung von NLP-Systemen wird durch die Entwicklung von Deep-Learning-Techniken vorangetrieben, aber es gibt auch einige Grenzen. Zum Beispiel wird das Problem des Verstehens erkannt, das darin besteht, dass Deep-Learning-Modelle zwar Muster in Daten erkennen können, aber nicht erklären können, wie sie zu ihren Ergebnissen kommen. Dies erschwert es, ihre Zuverlässigkeit und Fairness zu überprüfen oder zu verbessern.
2010er Jahre
Die Entwicklung von NLP-Systemen wird durch die Einführung der Transformer-Architektur vorangetrieben, aber es gibt auch einige Herausforderungen. Zum Beispiel wird das Problem des Datenhungers erkannt, das darin besteht, dass Transformer-Modelle zwar sehr leistungsfähig sind, aber auch sehr viele Daten benötigen, um trainiert zu werden. Diese Daten sind jedoch oft unvollständig, ungenau oder voreingenommen.
2020er Jahre
Die Entwicklung von NLP-Systemen erreicht einen neuen Meilenstein mit der Einführung von großen Sprachmodellen (LLMs), aber es gibt auch einige Bedenken. Zum Beispiel wird das Problem der Ethik erkannt, das darin besteht, dass LLMs zwar sehr beeindruckend sind, aber auch potenziell schädliche oder missbräuchliche Inhalte erzeugen oder verbreiten können. Dies wirft Fragen nach der Ethik und Verantwortung der Entwickler und Nutzer der Modelle auf.
Diese faszinierende Reise von der Grundlagenforschung in den 1950er Jahren bis zu den LLMs der 2020er Jahre hat die Art und Weise, wie wir mit natürlicher Sprache interagieren und sie verstehen, grundlegend verändert. Es bleibt spannend zu sehen, welche kulinarischen Höhepunkte die Zukunft der NLP noch bereithält.
Large Language Modelle
– Status Quo
Die Entwicklung von Large Language Modellen begann mit dem Erscheinen von Transformer-Architekturen, die die Lernfähigkeit dieser Modelle verbesserten. Ähnlich wie das Upgrade deines Computers mit schnelleren Prozessoren und mehr Speicher ermöglichten diese Architekturen den LLMs, effizienter und schneller zu lernen. Das erinnert an die Entwicklung von Autos mit fortschrittlicheren Motoren, die schneller und effizienter sind als ihre Vorgänger.
Ein Meilenstein in dieser Entwicklung war BERT (Bidirectional Encoder Representations from Transformers), ähnlich wie der Schritt von einem alten Handy zu einem modernen Smartphone. BERT konnte sowohl vor als auch nach einem Wort in einem Satz schauen, um den Kontext zu verstehen.
Das Jahr 2023 – Large Language Modelle im Boom!
Das Jahr 2023 ist ein markantes Jahr, in dem Schlag auf Schlag Neuentwicklungen entstehen. Hier die wichtigsten Veröffentlichungen von Large Language Modellen aus dem Jahr 2023.
Januar: Google veröffentlicht die „Flan 2022 Collection“ mit Fokus auf effektive Anweisungsabstimmung.
Februar
Meta stellt „LLaMA“ vor und Microsoft bringt „Kosmos-1“ heraus, beide verbessern die Grundlagen von Sprachmodellen.
März
Googles „PaLM-E“ führt verankerte multimodale Fähigkeiten ein, während OpenAI den „GPT-4 Technischen Bericht“ veröffentlicht.
April: „Pythia“ wird von EleutherAI und andere Autoren veröffentlicht. Das Papier behandelt, wie Sprachmodelle im Verlauf von Training und Skalierung analysiert werden kann.
Mai
Ein busy Monat mit „Dromedary„, Googles „PaLM 2 Technischer Bericht“, Receptance Weighted Key Value (RWKV) von Bo Peng und anderen Wissenschaftler, und Stanfords Direct Preference Optimization (DPO), veröffentlichten weitere Forschungsergebnisse in die LLM-Welt.
Juni
Kosmos-2 veröffentlicht. Verankerung von Multimodal Large Language Models in die Welt.
Juli
Meta veröffentlicht „LLaMA 2“ mit feinabgestimmten Chat-Modellen.
Im März 2023 präsentierte OpenAI GPT-4 als bedeutenden Fortschritt im Bereich des Deep Learning. Dieses Modell ist multimodal, akzeptiert sowohl Bild- als auch Texteingaben und erzeugt Textausgaben. GPT-4 übertrifft GPT-3.5 in menschenähnlichen Leistungen auf professionellen und akademischen Benchmarks.
Bis Oktober 2023 sind noch einige weitere Entwicklungen passiert.
Antropic bringt Claude 2 raus. Es ist eine verbesserte Version eines digitalen Helfers, der nun besser und schneller antwortet. Man kann ihn über eine Webseite oder eine spezielle Schnittstelle nutzen. Er ist besser in Sachen Rechnen und Logik geworden, und kann nun auch größere Texte verarbeiten und erstellen, wie zum Beispiel Briefe oder kleine Geschichten.
Das Mistral AI-Team hat eine neue Version ihres digitalen Helfers namens Mistral 7B herausgebracht. Dieser Helfer ist jetzt leistungsfähiger und besser als seine Vorgänger, sogar besser als andere vergleichbare Modelle. Er ist besonders gut darin, ähnlich wie ein Profi, Code zu schreiben.
Wie funktionieren Large Language Modelle?

Große Sprachmodelle (LLMs) sind eine Art künstlicher Intelligenzsysteme, die menschliche Sprachtexte verarbeiten und generieren. Sie arbeiten durch eine Kombination fortschrittlicher maschineller Lernmethoden, neuronaler Netzwerke und umfangreicher Datenverarbeitung. Hier ist eine vereinfachte Übersicht darüber, wie LLMs funktionieren:
Schritt 1: Daten sammeln
Der erste Schritt bei der Erstellung eines LLMs besteht darin, eine riesige Menge an Textdaten zu sammeln. Dies kann Bücher, Artikel, Websites, Social-Media-Beiträge und mehr umfassen. Je größer und vielfältiger der Datensatz ist, desto besser arbeitet das Modell.
Denke an LLMs wie an Meisterköche, die das perfekte Kochbuch erstellen möchten. Dafür sammeln sie Kochbücher, Food-Blogs und Speisekarten aus der ganzen Welt. Je mehr Rezepte sie sammeln, desto besser wird ihr Kochbuch.

Schritt 2: Texte tokenisieren
Die Textdaten werden in kleinere Einheiten namens „Tokens“ aufgeteilt. Tokens können Wörter, Teilwörter oder sogar Zeichen sein, je nach Architektur des Modells. Zum Beispiel könnte der Satz „Ich liebe Eiscreme“ in [„Ich“, „liebe“, „Eis“, „creme“] tokenisiert werden.
Genauso, wie die Köche die Zutaten in jedem Rezept in kleinere, mundgerechte Stücke schneiden, zerlegen LLMs die Textdaten in kleinere Einheiten namens „Tokens“. Diese Tokens sind wie die einzelnen Zutaten in einem Rezept, wie Wörter oder Phrasen. Dies erleichtert die Arbeit der LLMs mit dem Text.
Schritt 3: Modell entwerfen
LLMs werden in der Regel mithilfe von Deep-Learning-Architekturen entwickelt, wobei eine der beliebtesten die Transformer-Architektur ist. Transformer haben die Fähigkeit, weitreichende Abhängigkeiten im Text zu erfassen, was sie für Sprachaufgaben geeignet macht.
Stell dir die Küche der Köche als magisches Kochstudio vor. Es ist mit den neuesten Geräten und Werkzeugen ausgestattet, wie einem hochmodernen Ofen und einem super scharfen Messer. Diese Küche ist darauf ausgelegt, jede Art von Rezept zu bewältigen, von Spaghetti bis Sushi. Ähnlich verwenden LLMs eine spezielle Art von Küche namens „Transformer-Architektur“, die entwickelt wurde, um alle Arten von Sprachaufgaben zu bewältigen.
Schritt 4: Modell trainieren
Das Modell wird dann auf den tokenisierten Textdaten trainiert. Während des Trainings lernt das Modell, die Wahrscheinlichkeit des nächsten Tokens in einer Sequenz basierend auf dem vom vorherigen Token bereitgestellten Kontext vorherzusagen. Dieser Prozess beinhaltet die Anpassung der internen Parameter des Modells (Gewichte und Versatz) zur Minimierung von Vorhersagefehlern.
Die Köche üben, indem sie diese Rezepte immer wieder zubereiten. Sie achten darauf, welche Zutaten gut zusammenpassen und welche nicht. Allmählich werden sie Experten darin, köstliche Gerichte zuzubereiten. Ähnlich „üben“ LLMs, indem sie Textdaten lesen und verarbeiten. Sie lernen, wie Wörter und Phrasen zusammenpassen, und werden zu Experten in der Textverarbeitung und -generierung.
Schritt 5: Selbstüberwachtes Lernen (Self-Supervised Learning)
LLMs verwenden selbstüberwachtes Lernen, was bedeutet, dass sie keine beschrifteten Daten mit expliziten Antworten benötigen. Stattdessen lernen sie aus den Daten selbst, indem sie fehlende Wörter oder Tokens innerhalb eines Satzes vorhersagen. Zum Beispiel, bei dem Satz „Die Katze ____ auf der Matte“, sagt das Modell das fehlende Wort „sitzt“ basierend auf dem Kontext voraus.
Genauso wie die Köche erraten können, welches Zutat in einem Rezept fehlt, lernen LLMs vorherzusagen, welche Wörter in einem Satz als Nächstes kommen sollten. Wenn sie beispielsweise „Der Himmel ist“ sehen, können sie basierend auf dem Gelernten „blau“ vorhersagen.
Schritt 6: Feinabstimmung (Fine-Tuning)
Nach dem anfänglichen Training werden LLMs häufig für bestimmte Aufgaben weiter verfeinert. Dies umfasst zusätzliches Training auf einem kleineren, aufgabenbezogenen Datensatz. Zum Beispiel kann die Feinabstimmung für Übersetzungsaufgaben, Frage-Antwort-Aufgaben oder Textgenerierung durchgeführt werden.
Stell dir vor, die Köche entscheiden sich, Meister einer bestimmten Küche zu werden, zum Beispiel der italienischen. Sie verbringen extra Zeit damit, ihre Pasta-Gerichte zu perfektionieren, indem sie von italienischen Köchen lernen. Das ist ähnlich wie die Feinabstimmung eines LLMs für eine spezifische Aufgabe. LLMs können für bestimmte Aufgaben, wie Übersetzung oder das Beantworten von Fragen, weiter verfeinert werden, um noch besser in ihnen zu werden.
Schritt 7: Inferenz
Sobald das Modell trainiert und feinabgestimmt ist, ist es bereit für die Inferenz. Es nimmt einen Eingabetext oder eine Eingabeaufforderung entgegen und generiert eine Antwort oder Vervollständigung basierend auf seinem gelernten Wissen. Dies kann das Beantworten von Fragen, das Generieren von Text, das Übersetzen von Sprachen und mehr umfassen.
Wenn jemand die Köche nach einem Rezept fragt, kombinieren sie schnell ihr Wissen und erstellen vor Ort ein neues Gericht. Sie wissen genau, welche Zutaten sie verwenden sollen und wie sie sie zubereiten sollen. Ähnlich verwendet ein LLM, wenn Sie ihm eine Aufforderung oder Frage geben, sein Wissen, um eine Antwort oder einen Text sofort zu generieren.
Schritt 8: Dekodierung
Das Dekodieren ist der Prozess, bei dem die wahrscheinlichsten Tokens ausgewählt werden, um eine kohärente Antwort zu bilden. Es gibt verschiedene Dekodierungsstrategien, einschließlich Greedy-Suche (Auswahl des wahrscheinlichsten Tokens bei jedem Schritt) und Beam-Suche (Erkundung mehrerer Token-Optionen, um die beste Sequenz zu finden).
Manchmal müssen die Köche zwischen verschiedenen Zutaten wählen, um ein Rezept zuzubereiten. Sie wählen diejenigen aus, die am besten passen, ähnlich wie Sie Beläge für Ihre Pizza auswählen würden. LLMs verwenden einen Prozess namens „Dekodierung“, um die wahrscheinlichsten Wörter auszuwählen und eine kohärente Antwort zu erstellen.
Schritt 9: Ausgabeerzeugung (Output Generation)
Die Ausgabe des LLMs ist eine Sequenz von Tokens, die dann in menschenlesbaren Text umgewandelt wird. Dies ist die endgültige Antwort, die vom Modell generiert wird.
Die Köche servieren das köstliche Gericht, das sie zubereitet haben, und Sie können es genießen. Ähnlich generieren LLMs eine Antwort, wie das Beantworten einer Frage oder das Schreiben einer Geschichte, und präsentieren sie Ihnen in einem lesbaren Format.
Schritt 10: Iteration und Verbesserung
LLMs werden kontinuierlich durch iterativs Training und Feinabstimmungsprozesse verbessert. Sie können auch für spezielle Bereiche oder Aufgaben angepasst werden, um ihre Leistung zu verbessern.
Wie Köche, die immer wieder neue Rezepte und Techniken ausprobieren, werden LLMs immer besser. Sie lernen aus dem Feedback, das sie erhalten, und verbessern ihre „Kochkunst“ oder Textgenerierung im Laufe der Zeit.
Insgesamt sind große Sprachmodelle mächtige Werkzeuge für das Verständnis und die Generierung natürlicher Sprache, und ihre Fähigkeiten entwickeln sich weiter, während die Forschung und Entwicklung in diesem Bereich voranschreiten.
Herausforderungen und Grenzen von Large Language Modellen
Obwohl Large Language Modelle beeindruckend sind, sind sie nicht ohne ihre eigenen Herausforderungen und Grenzen:
Datenqualität
Die Qualität der Trainingsdaten ist entscheidend, ähnlich wie bei einem Künstler, der nur mit den besten Farben und Leinwänden arbeiten kann. Schlechte Daten könnten zu fehlerhaften Antworten führen.
Ethik und Verantwortung
Die Verwendung von LLMs wirft ethische Fragen auf, insbesondere wenn sie potenziell schädliche oder missbräuchliche Inhalte generieren können. Es ist wichtig, die Technologie verantwortungsbewusst einzusetzen und Missbrauch zu verhindern.
Verständlichkeit und Erklärbarkeit
Die Funktionsweise von LLMs ist oft schwer nachvollziehbar, ähnlich wie das Innenleben einer komplexen Maschine. Die Transparenz und Erklärbarkeit von Entscheidungen ist eine Herausforderung.
Der letzte Punkt wird unter anderem durch die sogenannte Halluzination verursacht. Hier erzeugen LLMs falsche oder erfundene Informationen, die nicht in den Trainingsdaten oder den dem Modell bereitgestellten Eingaben vorhanden waren. Es stellt eine bedeutende Herausforderung dar, da es zu Fehlinformationen oder Fehlinterpretationen führen kann, insbesondere in kritischen Anwendungsfällen wie medizinischen oder rechtlichen Anwendungen.
Stell dir vor, ein großes Sprachmodell ist wie ein Künstler, der ein Bild zeichnet, basierend auf den Beschreibungen, die du ihm gibst. Wenn deine Beschreibungen unklar sind oder der Künstler die Details missversteht, könnte er Elemente im Bild erfinden oder „halluzinieren“, die nicht in den ursprünglichen Beschreibungen vorhanden waren. So entstehen in LLMs Halluzinationen, wenn das Modell versucht, aus unvollständigen oder unklaren Informationen Sinn zu machen und dabei falsche oder erfundene Details erzeugt.
Fazit
Large Language Modelle sind wie die Magier der künstlichen Intelligenz, die die Grenzen unserer Vorstellungskraft überschreiten. Mit ihrer Fähigkeit, natürliche Sprache zu verstehen und zu generieren, haben sie zahlreiche Anwendungsfelder erobert. Dennoch sollten wir stets die Herausforderungen und Grenzen dieser faszinierenden Technologie im Auge behalten. Die Reise der Large Language Modelle ist noch lange nicht zu Ende, und sie versprechen weiterhin aufregende Entwicklungen in vielen Bereichen unseres Lebens.